
O uso de arquitetura em camadas no desenvolvimento de software é algo comum. Mas geralmente questões como responsabilidades e reutilização de cada camada é tratada de forma inadequada. O tema apresenta uma visão conceitual e evolutiva sobre o uso de camadas, destacando boas práticas, pontos de atenção e como trabalhar com questões como isolamento e dependências.
Arquitetura em camadas é um estilo arquitetural que dentre vários objetivos, destaca-se o de organizar as responsabilidades de partes de um software, normalmente criando um isolamento e dando um propósito bem definido a cada camada de forma que a mesma possa ser reutilizável por um nível mais alto ou até substituível.
Mas na prática, principalmente em aplicações corporativas, essas características se perdem em meio a códigos desorganizados e entendimento confuso sobre tais conceitos. Desta forma o tema resgata inicialmente um resumo da história e evolução do uso de camadas.
O uso do conceito de camadas é algo antigo, amplamente utilizado antes mesmo de se tornar popular na engenharia de software. Dentre exemplos conhecidos, pode-se citar:
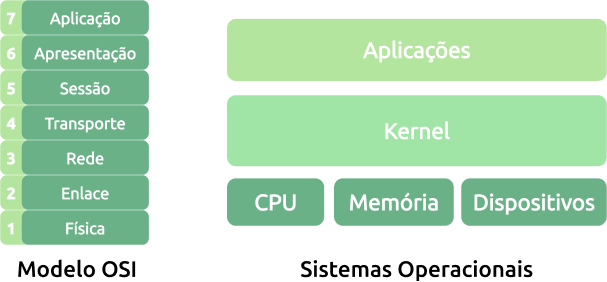
- Modelo OSI, criado ainda na década de 70 e que na década de 80 virou o modelo de rede padrão para protocolos de comunicação.
- Sistemas operacionais: O uso de camadas por sistemas operacionais permitiu a padronização e evolução com relação a construção e uso de CPU, memória, dispositivos, kernel e aplicações.
Ambos exemplos estão representados na figura abaixo:
Em aplicações corporativas, conforme apresentado no livro Padrões de Arquitetura de Aplicações Corporativas, o uso de camadas ganhou destaque na década de 90, com a adoção de sistemas cliente-servidor, os quais são divididos em duas camadas, sendo o cliente com a interface do usuário e código de aplicação e no lado servidor um banco de dados para persistência.
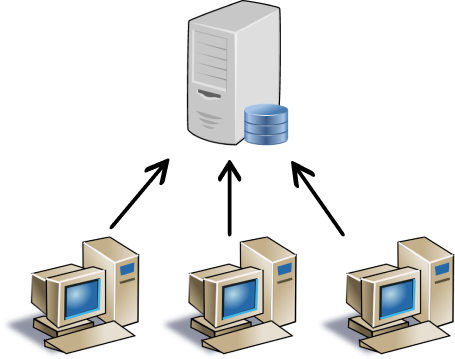
Esse modelo foi um dos impulsionadores para os modelos atuais utilizados já na computação em nuvem. No modelo cliente-servidor, com a evolução do lado cliente com novas interfaces para o usuário e no lado servidor com amadurecimento da computação distríbuida, surgiu a questão: onde colocar o código referente a lógica de negócio?.
No início esse código foi escrito ou no lado do cliente, junto ao código das interfaces do usuário, ou no lado servidor, geralmente nos bancos de dados. O que por muito tempo contribuiu para que fossem gerados códigos desorganizados e repetidos, uma herança que ainda assombra muitos times de desenvolvimento.
Na curva de evolução, vieram os sistemas divididos em 3 camadas que somado a uma popularização do uso de OO (Orientação-Objeto) contribuíram para a lógica de negócio ser separada em uma camada própria, normalmente sendo executada no lado servidor.
A consolidação da arquitetura de camadas em aplicações corporativas veio com advento da Web. A necessidade de trabalhar com a interface para o usuário através de browsers colocou à prova algumas vantagens que o uso de camadas oferece. O resultado não foi animador, poucas soluções tiveram êxito em reutilizar por completo suas camadas dedicadas à lógica de negócio.
O histórico da evolução de camadas e a forma como times de desenvolvimento têm implementado código retornam o foco a duas questões já citadas: organizar as responsabilidades do código e reutilizar camadas.
Soluções rodando em browsers, celulares e outros dispositivos, a evolução da arquitetura de camadas para N camadas, a evolução da computação distríbuida, outros estilos e padrões de arquitetura e por último a popularização do uso de Cloud mostraram que o uso de camadas tem grande valor e pode ter sido compreendido por times de desenvolvimento, mas na prática, os códigos implementados não expressaram isso. Muitas soluções possuem problemas com relação ao uso de camadas.
Código repetido na interface do usuário, problema de isolamento entre camadas, camadas pouco reutilizáveis e menos ainda substituíveis, e até dificuldade na compreensão entre a diferença da divisão física e lógica de camadas, são os problemas comuns e uma fonte de dívidas técnicas, bugs e empecilho para escala de softwares e times de desenvolvimento.
Divisão física e lógica
No idioma inglês há dois termos que referentes a camadas, o Tier e Layer, os quais no idioma português possuem a mesma tradução: camadas. É comum desenvolvedores(as) fazerem uma confusão quando se referem a camadas sem destacar o que é a divisão física e lógica, e isso no idioma português fica mais acentuado. Tier refere-se a physical unit que é a divisão física, e o Layer refere-se a logical unit que é a divisão lógica.
Não estar atento a essa diferença pode gerar decisões de arquitetura e design equivocadas que irão refletir na implementação do código e principalmente no desempenho de execução do software.
☛ Divisão física (Tier)
Uma camada pode ser considerada física quando ela é executada em processos ou máquinas diferentes. Nestes casos normalmente as chamadas e trocas de dados entre as camadas são através de algum protocolo de comunicação, o que também provavelmente envolverá serialização/deserialização de dados. Se estiverem em máquinas diferentes os dados irão trafegar pela rede, ou seja, quanto mais distante, maior a chance de degradação de performance do software como um todo.
O modelo cliente-servidor, por exemplo, é considerado um modelo two-tier systems, pois rodam normalmente em máquinas diferentes. E mesmo que estejam na mesma máquina ainda assim são processos distintos em execução no sistema operacional.
Aplicações web tradicionais também estão geralmente divididas em camadas físicas, conforme exemplo abaixo:
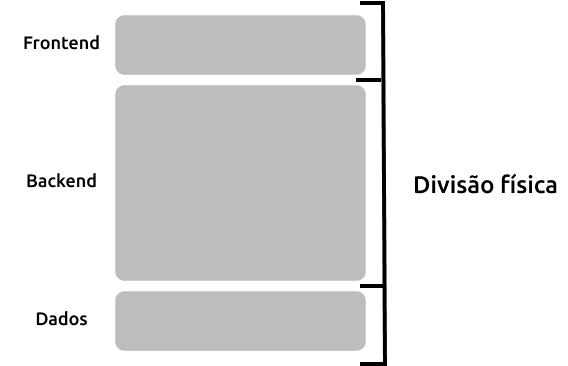 O ponto de atenção para desenvolvedores(as) é observar que entre camadas físicas a comunicação pode gerar degradação de performance. Um exemplo comum é com a camada de dados, onde quando há excesso de consultas a uma fonte de dados e a comunicação através do uso de rede, normalmente há comprometimento de performance do software.
O ponto de atenção para desenvolvedores(as) é observar que entre camadas físicas a comunicação pode gerar degradação de performance. Um exemplo comum é com a camada de dados, onde quando há excesso de consultas a uma fonte de dados e a comunicação através do uso de rede, normalmente há comprometimento de performance do software.
☛ Divisão lógica (Layer)
Uma camada pode ser considerada lógica quando ela é executada junto ao mesmo processo de outras camadas (superior ou inferior). Nestes casos normalmente as chamadas e trocas de dados entre as camadas são através da invocação de métodos dentro de um mesmo processo em execução da máquina virtual utilizada. Poderá haver conversão de dados (tipo ou estrutura) entre as camadas, mas normalmente não há necessidade de serialização/deserialização de dados. Estando em execução no mesmo processo, a comunicação entre as camadas é rápida, dificilmente há problemas de performance no software em função desta comunicação.
Uma camada física pode conter várias camadas lógicas. O backend de soluções web, são um bom exemplo de camadas lógicas, conforme exemplo abaixo:
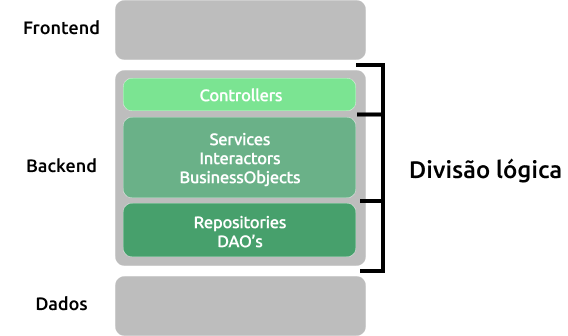
Modelos tradicionais
O modelo mais tradicional utilizado atualmente em arquiteturas de camadas para soluções corporativas é o de 3 camadas físicas. Um modelo exemplificado nas figuras do tópico anterior e bastante aderente para web, celulares e até desktop. Suas camadas são representadas por algumas nomenclaturas diferentes, mas tradicionalmente conhecidas por camadas de apresentação, lógica de negócio e dados.
Cada camada desta pode também possuir suas camadas lógicas, o que variando a quantidade de camadas pode fazer o software ser considerado de N camadas. A seguir os subtópicos detalham melhor essas camadas.
Apresentação
A camada de apresentação, que inclui o frontend (termo amplamente utilizado atualmente), trata da interação do usuário com o software. A interface para tal pode ser um “cliente rico”, que antigamente era um termo associado a telas desktop, mas que hoje representam interfaces web, normalmente baseadas em html e javascript, e interfaces para celulares as quais podem estar baseadas em html responsivo ou estarem implementadas utilizando linguagens nativas para Android, iOS, dentre outros.
Uma interface de interação com o usuário também pode ser algo muito simples, como uma linha de comando em um sistema operacional, ou sequer precisa da interação de um usuário humano, podendo ser chamado através de scripts automatizados.
Em qualquer destas opções, há um consenso: a camada de apresentação não deve conhecer lógica de negócio!
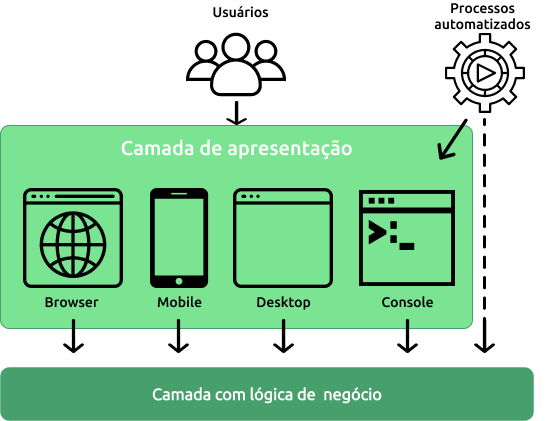
Ela deve ser capaz de capturar os comandos do usuário, converter isso em ações sobre a camada de negócio, e exibir as informações resultantes ao usuário. Toda inteligência desta camada deve estar associada a usabilidade para usuário. Todos os tipos de apresentação devem poder executar exatamente as mesmas ações da camadas de negócio e receber um resultado que possa ser apresentado ao usuário.
Essencialmente, a camada de apresentação precisa:
- Mostrar ao usuário que informações de entrada são necessárias.
- Capturar essas informações.
- Agrupar, formatar e converter as informações conforme a camada de negócio espera receber.
- Enviar as informações para a camada de negócio.
- Processar o resultado formatando e agrupando as informações da melhor forma para exibição ao usuário.
- Exibir o resultado, seja ele de sucesso ou erros.
A nível de código, deve-se evitar:
- IF’s, ou outras condições e lógicas relacionadas à validação de dados que a camada de negócio deve validar.
- Conversões de dados que devem ser realizadas na camada de negócio
- Chamadas a vários métodos na camada de negócio que representam um mesmo caso de uso ou regra de negócio.
- Acesso a camadas inferiores a de negócio (exceto se o isolamento for flexível, o que é melhor explicado em um tópico adiante).
- Integrações com serviços externos sem passar por uma camada inferior adequada para isso.
- Ações como notificações a clientes, chamadas a processos paralelos, dentre outros.
A camada de apresentação pode ter camadas lógicas, o que normalmente é algo proposto por vários frameworks focados na camada de apresentação.
Lógica de negócio
A camada de negócio, também popular pelo termo camada de domínio, é a que possui o código referente à lógica do negócio para qual o software foi concebido. Pode-se afirmar que dentre as camadas, é a mais relevante para uma empresa.
Espera-se que na camada de negócio, normalmente estejam implementados:
- Os “contratos” relacionados aos dados de entrada para as funcionalidades esperadas.
- As validações dos dados de entrada.
- Os cálculos, regras e lógicas referentes a composição e estruturação dos dados seguindo o modelo de domínio.
- O envio dos dados para persistência.
- A recuperação de dados, agrupando-os e organizando-os de acordo com modelo de domínio.
- O retorno estruturado de dados para camadas superiores, mesmo que sejam erros relacionados a algum problema nas regras aplicadas.
Quando bem implementada, normalmente esta camada é a que tem maior tempo de vida sem requerer mudanças por surgimento de novas tecnologias. As mudanças nela são geralmente em função de evoluções ou mudanças no negócio.
Porém, na prática um cenário comum é softwares possuindo uma camada de negócio pouco reutilizável e frágeis a qualquer mudança tecnológica. Algumas situações corriqueiras:
- Mudanças de versão de frameworks afetando código de negócio.
- Surgimento de novos frameworks e times de desenvolvimento reescrevendo código de negócio.
- Mudanças no código de negócio em função de mudanças em outras camadas, como melhorias de usabilidade na camada de apresentação.
- Incertezas com relação a mudanças no código de negócio quando necessário, como:
- A mudança quebrará outras camadas?
- A mudança será o suficiente naquele ponto ou será necessário revisar as demais camadas?
- Qual o impacto de uma mudança nas demais regras de negócio?
A camada de negócio pode ser física ou lógica, e ela mesma possui normalmente várias camadas lógicas na sua composição. É uma camada propícia para o uso de padrões de arquitetura e de projeto. Abaixo 2 exemplos dentre as muitas variações normalmente encontradas nas implementações de uma camada de negócio.
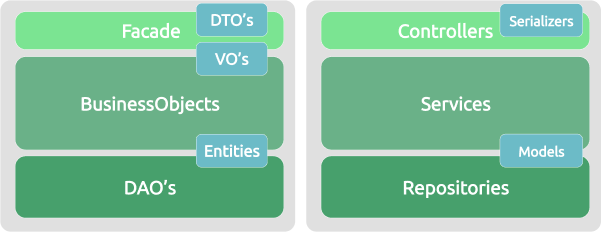
Durante o processo de amadurecimento na utilização destas camadas e padrões nas mais diversas linguagens e frameworks, muitas variações e até interpretações inadequadas surgiram. Mas independente dos modelos e padrões já experimentados e das preferências pessoais de desenvolvedores(as), há um consenso com relação a composição geral desta camada:
- As camadas lógicas auxiliam na organização e responsabilidade do código.
- Para a comunicação com a camada de apresentação, é importante ter uma camada de controle.
- A entrada de dados na camada de controle não é necessariamente a estrutura que será usada para persistência, logo:
- Pode-se usar um objeto simples para transferência de dados que será convertido para um objeto a ser usado na lógica de negócio e persistência.
- Pode-se usar um formato padrão para troca de informações, como JSON ou XML, e serializar os dados para um objeto a ser usado na lógica de negócio e persistência.
- As regras de negócio devem estar em uma camada focada somente no domínio do software.
- As regras de persistência devem estar em uma camada focada somente em interagir com bancos de dados ou outras formas de armazenamento.
Essas questões valem para grande parte das variações de modelagem desta camada. Há claro outros detalhes menores como mapeamentos ORM, uso de outros padrões, uso de mais camadas intermediárias, uso de linguagens funcionais, dentre outros. O grande ponto é compreender a lógica básica aplicada nesta camada e independentemente da modelagem definida, garantir que ela possa ser reutilizável por camadas superiores e organizada com relação às responsabilidades de cada parte do código.
Dados
A camada de dados geralmente é associada a persistência em um banco de dados, o que é uma verdade em grande parte das aplicações corporativas. Porém essa camada pode ser representada por qualquer outra ferramenta e/ou sistema que possa prover os dados para as demais camadas.
Nesta abordagem, pode-se considerar também outros meios de persistência como:
- Sistemas de cache.
- Sistemas de mensageria.
- Buckets de arquivos.
- Sistemas terceiros.
- Arquivos de texto plano em um disco rígido (uma opção pouco válida para aplicações corporativas).
O grande benefício dela é isentar a lógica de negócio da responsabilidade de saber como persistir os dados em um local físico. Os bancos de dados predominaram nesta camada durante décadas, mas recentemente, apoiadas sobre o crescimento das infraestruturas de cloud, outras ferramentas ganharam espaço e têm se provado boas alternativas dependendo da necessidade do negócio.
Normalmente esta é uma camada física, logo a comunicação com ela envolve dados trafegados pela rede, o que torna necessário estar atento a duas questões a seguir.
☛ Quantidade de requisições à camada de dados
A quantidade está relacionada ao número de chamadas que são realizadas à camada de dados a partir de uma única ação do usuário. Um exemplo comum é:
Usuário deseja ver a lista de pedidos em aberto da sua loja, ao clicar no botão consultar, o sistema executa:
- A apresentação envia o filtro utilizado junto a requisição feita para consultar os dados.
- O negócio recebe o filtro, valida e faz a requisição dos dados à camada de dados.
- A camada de dados, aplicando o filtro, retorna 25 pedidos em aberto.
- O negócio agora tem os dados dos pedidos, mas precisa também dos dados do cliente e itens de cada pedido, logo faz uma nova requisição a camada de dados para cada item.
- No retorno para o usuário será necessário apresentar também o endereço do cliente, então para cada cliente será necessário uma nova requisição para os dados de endereço.
Apenas nesse cenário simples, considerando a pior situação com relação a implementação e pedidos de 25 clientes diferentes, essa simples ação do usuário poderia gerar 76 requisições a camada de dados.
Não parece uma lógica muito eficiente, mas é um cenário comum em muitas aplicações, principalmente nas que utilizam ORM (Mapeamento Objeto/Relacional) (que não é o problema), e sim a pouca atenção com relação a como a camada de negócio está se comunicando com a camada de dados.
Estratégias inadequadas com relação a quantidade de requisições a camada de dados são causadores de degradação em muitos dos softwares que apresentam problemas de performance.
A solução com relação a estes casos pode variar de acordo com o tipo de fonte de dados, mas normalmente demanda:
- Revisões na modelagem de dados, desnormalizando informações.
- Revisões de Queries de consulta, buscando fazer junções de dados e outras estratégias que tragam as informações necessárias na mesma requisição.
- Revisões no ORM (quando utilizados), adequando mapeamentos Lazy Loading.
- Uso de lógicas no código que priorizem ir menos vezes a camada de dados, fazendo uso de caches ou outras estratégias.
☛ Volume de dados enviados ou recebidos delas
O volume está associado ao tamanho do pacote de dados a ser enviado ou recebido na comunicação com a camada de dados em uma única requisição. Um exemplo deste cenário:
Usuário deseja ver a lista de pedidos entregues da sua loja, ao clicar no botão consultar, o sistema executa:
- A camada de apresentação envia os dados do filtro utilizado junto a requisição feita para consultar os dados.
- A camada de negócio recebe os dados, faz algumas validações e faz a requisição dos dados a camada de dados.
- A camada de dados, aplicando o filtro, retorna 850 pedidos em aberto.
- A camada de negócio agora possui lógica para fazer poucas requisições a camada de dados, porém não há tratamento de paginação para o resultado.
- Como retorno para o usuário será enviado um conjunto grande de dados, o que provavelmente impactará no tempo de resposta.
Mesmo estando atento à questão da quantidade de requisições, também é necessário estar atento ao volume de dados retornados.
Estratégias inadequadas com relação ao volume de dados são menos comuns do que a relacionada à quantidade de requisições, mas ainda assim ocorrem quando não há atenção a ela e o resultado também será de degradação da performance do software.
A solução com relação a estes casos pode envolver:
- Revisões sobre quais dados realmente são necessários no retorno. Toda informação não utilizada pode ser reconsiderada.
- Fragmentar consulta aos dados, porém mantendo atenção a quantidade de requisições a serem realizadas.
- Manter cache na camada de negócio de dados que estejam repetidos no retorno, de forma que não precisem ser solicitados a camada de dados.
Isolamento
Uma das vantagens no uso de camadas é poder isolar a complexidade e os detalhes de uma camada para as demais. Isso é bastante útil para manter a ordem no código e também no fluxo de execução do software. Porém é preciso estar atento às definições planejadas de isolamento, pois não são todas as linguagens e frameowrks que permitem um isolamento total, incluindo a nível de código, e assim pode ser fácil desenvolvedores(as) extrapolar esse isolamento, muitas vezes sem perceberem.
Uma regra geral é: uma camada pode conhecer camadas inferiores, porém não pode conhecer camadas superiores, ou seja, ela não deve fazer chamadas a recursos de uma camada superior. Isso vale para situações como:
- Chamada de métodos.
- Importação de classes e/ou outros artefatos.
- Recebimento de dados em estruturas definidas e/ou implementadas por uma camada superior.
- Retorno de dados em estruturas definidas por uma camada superior.
Camadas com isolamento estrito ou flexível
O isolamento estrito, parte do princípio: uma camada pode conhecer apenas a camada inferior imediata, ou seja, a camada inferior do segundo nível em diante não pode ser acessada pela camada em questão.
Esse modo de isolamento cria mais de burocracia com relação a implementação de código, o que não é necessariamente negativo, mas sim uma característica a ser ponderada por desenvolvedores(as). Exemplo, um Controller deve sempre acessar um Service para que este acesse um Repository.
Já o isolamento flexível, permite uma camada conhecer várias inferiores.
Esse modo de isolamento pode simplificar a codificação permitindo que menos código seja escrito para que uma camada execute ações que já estão mapeadas em camadas inferiores do segundo nível em diante. Exemplo, um Controller acessando diretamente um Repository para enviar ou recuperar dados.
A figura abaixo explicita a diferença entre os dois modos de isolamento.
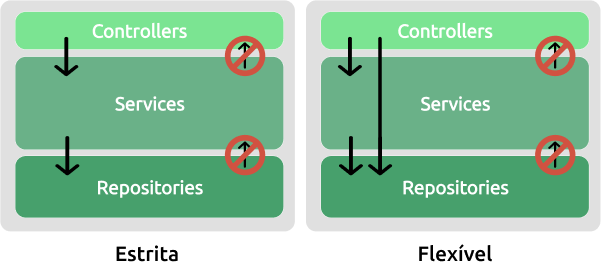
Dependências
Considerando os modos de isolamento, o primeiro ponto com relação a dependências é que uma camada não pode depender de uma camada superior. Isso se encaixa nos contextos:
- De compilação: uma camada não pode ter dependências com relação a compilação de uma superior.
- De execução: ao executar o software, uma camada não pode depender que uma superior esteja em execução.
Na dependência de camadas inferiores, elas podem variar quando são estritas ou não estritas.
Com isolamento estrito, uma camada deve depender apenas do código referente a sua inferior imediata. Isso garante um melhor fluxo de dependência entre as camadas, de forma que uma camada precisa estar atenta apenas à composição e mudanças do primeiro nível inferior.
Com isolamento flexível, uma camada pode acabar dependendo de várias outras inferiores, o que requer maior atenção à composição e mudanças. Exemplo, uma mudança em um Reporitoty pode tornar necessário a refatoração de um Controller.
Inversão de dependência
A inversão de dependência (Dependency Inversion Principle - DIP), em OO (Orientação/Objeto), é um dos princípios SOLID, ela resumidamente estabelece que módulos de alto nível não devem depender de módulos de baixo nível; ambos devem depender de abstrações, o que é bastante válido em arquiteturas modulares, e que também pode ser uma boa prática no uso de camadas.
Mas ao considerar que uma camada não pode depender de uma superior, como fazer para ter uma “inversão de dependência”?
A chave está em criar uma abstração dos contratos estabelecidos entre as camadas, o que na maioria das linguagens irá resultar no uso de interfaces ou classes abstratas. Feito isso, a camada inferior deve conter implementações concretas das interfaces e a camada superior deve apenas obter instâncias da implementação concreta. A figura abaixo exemplifica isso:
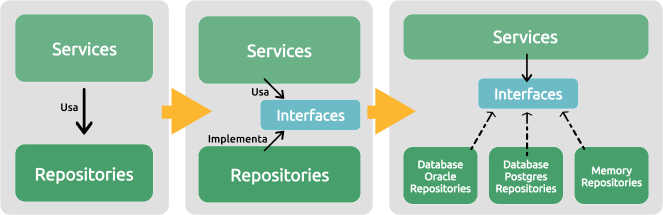
Desta forma é possível a exemplo da figura acima colocar em prática uma característica e vantagem já citada, que é poder substituir uma camada. A camada Service pode definir se deseja usar um repositório para Banco de dados Postgres ou Oracle.
Injeção de dependência
Ao fazer inversão de dependência, as implementações de uma camada superior não deverão mais conhecer de forma explícita as implementações concretas da camada inferior. Todo código escrito na camada superior deve considerar apenas as abstrações que normalmente estarão representadas por interfaces.
Porém, ao executar o software, uma instância de uma implementação concreta ainda precisa ser carregada nos pontos de referências às interfaces, desta forma em algum momento “alguém” precisa criar e injetar essas instâncias, já que o código não pode fazê-las explicitamente. Para isso há o padrão de projeto de injeção de dependência.
Esse padrão, maduro em várias linguagens como Java e .Net, é uma das formas de trabalhar com o princípio de inversão de dependência.
Neste caso o software contará com um Injector, e no momento de criação dos Services, o Injector criará uma instância da implementação concreta do Repository configurado e injetará essa instância na referência da interface utilizada pelo Service. A figura abaixo exemplifica:
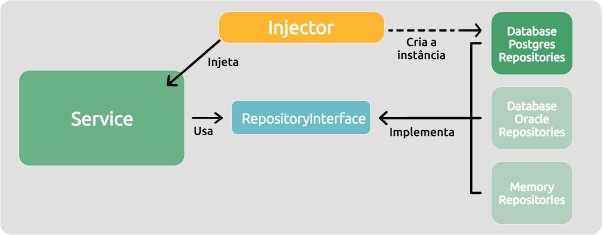
Na figura o repositório configurado é o DatabasePostgresRepository, desta forma o Injector se responsabilizará por criar a instância do mesmo e injetá-la para que o Service possa utilizá-la. A forma de configuração irá variar de acordo com linguagem e biblioteca de injeção de dependência utilizada, mas normalmente se dá por arquivos de configuração ou anotações diretamente no código.
Unindo a inversão e injeção de dependência, é possível trabalhar com camadas de forma que as mesmas sejam substituíveis.
O uso de camadas ainda é algo importante na organização e estruturação de um software, e quando bem utilizada contribui para que partes do software sejam reutilizáveis e substituíveis, o que indiretamente reflete em menos refatorações, maior velocidade dos times de desenvolvimento e entregas com software de maior qualidade.
Em arquiteturas de software mais recentes, há outros padrões que podem ser conciliados ao uso de camadas, o que é apresentado no guia no tema próprio Camadas e padrões de arquitetura.
Acesse os links abaixo para se aprofundar mais sobre conteúdos citados nesse tema!
- Modelo OSI (acrônimo do inglês Open System Interconnection), um modelo de rede padrão para protocolos de comunicação.
- Modelo cliente-servidor, artigo da wikipedia detalhando o tema.
- Livro Padrões de Arquitetura de Aplicações Corporativas
Confira todos os links à conteúdos externos citados nos temas do guia dev!
- 01/02/2021 - Publicação do tema. Autor: Isaac Felisberto de Souza